23. Parallelization¶
In Fig. 11.2 we could see that some of the items were marked with an asterisk (*). This indicates that the subtask is a potential target for parallelization. In this section the various tasks will be dissected in more detail.
AGX is built upon the notion of tasks. A task can depend on other tasks and can also have sub-tasks. A Task which does not depend on other tasks can run in parallel with other tasks.
For example the class DynamicsSystem is built upon several tasks and subtasks. Such as “UpdateWorldMassAndInertia”, “IntegrateVelocity”, etc. Many of these tasks will split up the work and execute in parallel. Another important feature of AGX is that all of the critical data for rigid bodies, shapes etc. are stored in buffers. These buffers are memory allocation blocks, aligned in memory appropriately for SSE optimization. Also, the memory can be made available for other implementation platforms such as OpenCL or CUDA. The executional part of a task is called a kernel. It can have several implementations, SSE, non-SSE, OpenCL, OpenGL etc. Which type of implementation that is needed, is selected when the task/kernel is initialized. A kernel is a small executional unit which operates on indata and supplies the result as out-data. It operates directly on the buffers for the fastest possible data access. This schema makes it possible to have some kernels executing on the graphics cards (for example OpenCL kernels), and some on the CPU.
23.1. Threads¶
In AGX there is a pool of threads used for all threaded jobs. The size of this pool is controlled with the call:
agx::setNumThreads( int n );
A negative value for n means that one thread is created per Core/CPU. The default value is 1. All parallelizable tasks are job-oriented. All jobs are put into a queue and scheduled for execution.
23.1.1. Executing AGX in threads¶
AGX creates and manages its own threads in a thread pool. However, to use the AGX API you need to be aware of a few things:
Any thread that calls the AGX API need to be registered as an AGX thread. This is because various resources need to be available for each thread. To promote a thread to be an AGX Thread call:
agx::Thread::registerAsAgxThread();To unregister a thread, call:
agx::Thread::unregisterAsAgxThread();
Callbacks from AGX such as contact events (11.4.3) or from event listeners (11.4.6) will always be done to the main thread for an agxSDK::Simulation. This is the thread that created the agxSDK::Simulation object. To make a thread the main thread for a simulation call (after a call to registerAsAgxThread()):
simulation->setMainWorkThread( agx::Thread::getCurrentThread() );
For an example of this, see tutorial_threads.cpp
23.2. Parallel tasks¶
Table 20 below; show some of the tasks which are parallelizable. These tasks will however not run in parallel to each other, as they depend on data from the previous task. Compare to the time line for the call to Simulation::stepForward() (Fig. 11.2).
Name |
Description |
Belongs to |
|---|---|---|
NarrowPhase |
Calculates contact data between two overlapping Geometries. |
agxCollide::Space |
Update bounding volumes |
Update bounding volumes for geometries. |
agxCollide::Space |
ApplyGravity |
Add gravitational force to bodies. |
agx::DynamicsSystem |
Solver |
Solve the constraint system. |
agx::DynamicsSystem |
IntegratePositions |
Integrate transformation and calculate acceleration. |
agx::DynamicsSystem |
IntegrateVelocity |
Integrate Velocity |
agx::DynamicsSystem |
UpdateWorldMassAndInertia |
Will calculate various items needed for the solver. |
agx::DynamicsSystem |
The Solver stage is only parallelizable if the partitioner can create disjoint groups of bodies which can be solved independently from each other.
23.2.1. NarrowPhase¶
This task will be given a list of overlapping bounding volumes (from the broad phase) calculate the exact contact data for two possibly overlapping geometries. This is a trivially parallelizable task, as there are no data dependency between the different overlapping geometries.
23.2.2. Update bounding volumes¶
This task will update the current bounding volume for a geometry (including its shape transformation and size). Depending on the frame hierarchy, this task can occupy quite some time for a large number of geometries. There are no data dependencies between the geometries. It can therefore be parallelized.
23.2.3. Partitioner¶
Based upon the connectivity in the whole dynamics system, the partitioner can split the system into independent sub-systems.
Two bodies are connected if there is a constraint between them. Constraints including contacts can create large trees of interconnected bodies.
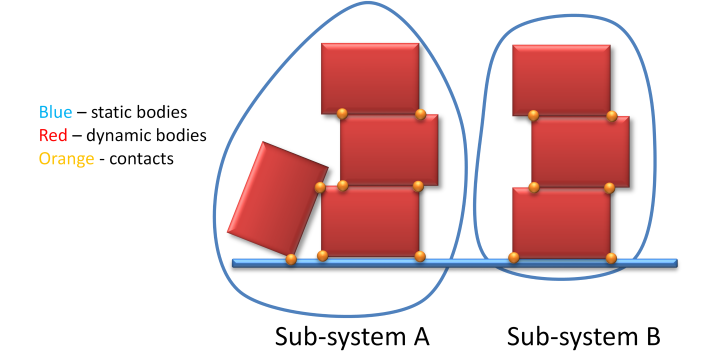
Fig. 23.1 Two separate subsystems.¶
In the figure above, two separate systems can be identified which can be solved independently from each other, hence the above system would gain if the solver would run the two systems in one thread each. As soon as there is a connection (through a constraint/contact) between two systems, they are merged. Kinematic bodies will analogous to static bodies split a system into two parts allowing for parallelization.